1.官方版NSQ存在的问题
在暑期实习期间,我粗略学习了一下 Kafka、NSQ、Hippo,并对它们的基础组件或者特性做了总结,但忽略了很重要的一点:把 Kafka、NSQ 进行对比,看看各自的优缺点。这部分的学习,对后来我完成组里事件中心的 Agent 组件起到了不小的帮助。
存储Message的额外消耗
| Kafka |
官方版本NSQ |
有赞版本NSQ |
| 至少26字节 |
24字节 |
16字节 |
主要特性
| \ |
NSQ |
Kafka |
| 数据安全 |
内存存储,超出Channel容量后,磁盘存储,不支持热备 |
磁盘存储,多节点互备 |
| 依赖 |
无 |
JDK、Zookeeper |
| 性能 |
十万级 |
百万级 |
| 刷盘机制 |
异步刷盘 |
异步刷盘 |
| 投递语义 |
至少一次 |
准确一次 |
| 消息顺序 |
不保证有序 |
支持有条件的有序 |
| 配置 |
不到五十项 |
数百个配置项 |
| 异常排查 |
源码量小,排查容易 |
源码量巨大,排查困难 |
其实,Kafka、NSQ 各有优势,本身都是非常优秀的产品。但是,NSQ 作为分布式消息中间件最致命的是节点异常情况下的数据丢失问题。
这里推荐一篇官方版本 NSQ 源码相关的文章,小米信息部技术团队的走进 NSQ 源码细节,可以先看官方版的实现,也可以先看本文,再和官方版对比一下,加深感受。
2.有赞版本的NSQ
据有赞团队自己的官方博客详细介绍了为什么要重新设计 NSQ,主要有以下几点原因:
- 部署不容易;
- 异常丢失;
- 难以追踪消息状态;
- 难以使用的历史消息;
- 难以按顺序接收消息;
- 难以在线调试。
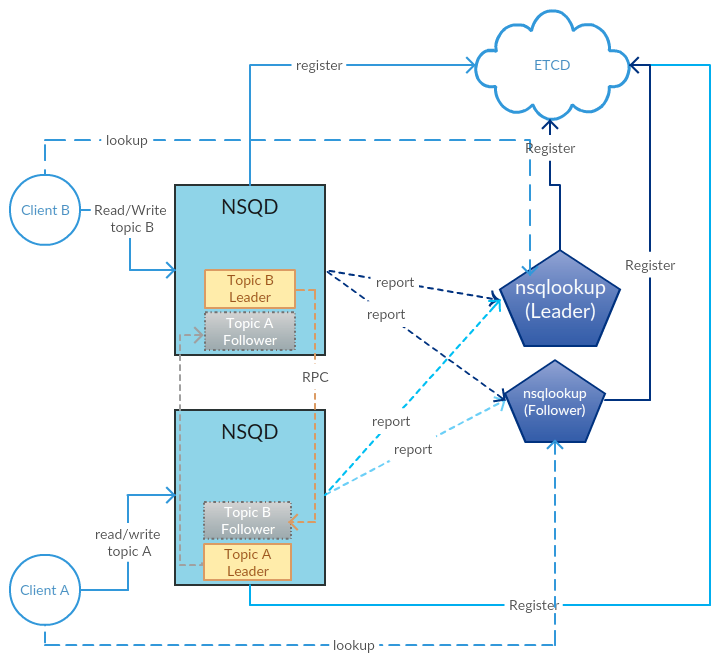
最终,有赞团队给出了如下的设计架构,可以看出他们借鉴了不少 Kafka 的设计思路:
2.1.源码目录结构
从有赞版本NSQGithub主页下载源码,可以看到如下的目录结构:
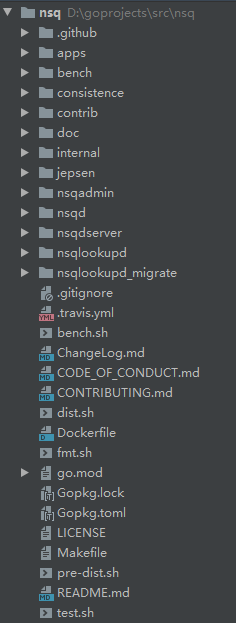
从上面的目录可以很清晰的感觉几个关键组件 nsqd、nsqlookupd、nsqadmin,而解决异常丢失的关键点,肯定是 nsqd,所以不妨从它如何启动开始看起。
apps 实际上是各个程序的入口;consistence 目录应该是有赞为实现可靠的一致性,而进行改造的代码;internal 应该是 nsqd 需要用到的 HTTP 或 TCP 的一些基础封装;Jepsen 则是对分布式测试的支持。而 nsqd 与 nsqdserver 的区别是,前者更加专注于 NSQ 功能的实现,后者则是 HTTP 或 TCP 接入层面的一些预处理。其他目录则基本不是代码文件存放的目录,做其他用途。
目录结构是阅读源码后,自行总结 + 猜测得出的大致用途,如有偏差、错误或者遗漏,还请前辈们指出。
2.2.nsqd的启动
用于启动的源码,位于 /apps 目录下,具体到 nsqd 就是位于 /apps/nsqd 目录下的 nsqd.go 文件中。其Main函数如下,NsqdServer 正是封装在 program 结构体中:
1 2 3 4 5 6 7 8
| func main() { defer glog.Flush() prg := &program{} if err := svc.Run(prg, os.Interrupt, syscall.SIGTERM, syscall.SIGHUP, syscall.SIGQUIT, syscall.SIGINT); err != nil { log.Panic(err) } log.Println("app exited.") }
|
nsqd 的初始化、启动、停止,运用了 go-svc 作为基础组件,据 go-svc 的Github介绍,它可以与Linux配合使用的Windows Service包装器。而 program 实现了如下的接口:
1 2 3 4 5 6 7 8 9 10 11 12
| type Service interface { Init(Environment) error Start() error Stop() error }
|
Main函数中调用的 Run 方法,正是位于依赖库的 svc\svc_windows.go 中。它将传入的 Service 封装到 windowsService 中,并调用 Init 方法,判断是否以Windows窗口方式运行,然后进行 run 方法,这才是启动的核心:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| func Run(service Service, sig ...os.Signal) error { ... ws := &windowsService{ i: service, isInteractive: interactive, signals: sig, } if err = service.Init(ws); err != nil { return err } return ws.run() }
|
run 方法源码如下,区别两种运行方式。其中,以Windows窗口方式运行时,调用 svcRun,其本质是调用依赖库的 windows\svc\service.go 的 func Run(name string, handler Handler) error 函数。但两者最终的核心都是调用 windowsService 中封装的 Service 的 Start 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| func (ws *windowsService) run() error { ws.setError(nil) if ws.IsWindowsService() { runErr := svcRun(ws.Name, ws) ... return nil } err := ws.i.Start() ... err = ws.i.Stop() return err }
|
由于如何调用到 Start 方法和 Stop 方法不是本次学习的重点,就不做更加详细的展示了。启动 nsqd 的核心在于 Start 方法,其代码如下。这里提一句,在 NewNsqdServer 函数中,有一行代码很重要 s.ctx.nsqd.SetPubLoop(s.ctx.internalPubLoop),记住它,后面会再次讲到。
1 2 3 4 5 6 7 8 9 10 11
| func (p *program) Start() error { ... nsqd, nsqdServer, err := nsqdserver.NewNsqdServer(opts) ... nsqdServer.Main() p.nsqdServer = nsqdServer return nil }
|
接下来,看看 Main 方法具体做了什么。其实,Main 方法就是监控TCP、HTTP、HTTPS的指定端口,完成 nsqd 的启动。nsqd 主要在2个TCP端口监听,一个给客户端,另一个是 HTTP API。同时,它也能在第三个端口监听 HTTPS。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
| func (s *NsqdServer) Main() { ... if s.ctx.nsqdCoord != nil { err := s.ctx.nsqdCoord.Start() ... } ... tcpListener, err := net.Listen("tcp", opts.TCPAddress) ... s.waitGroup.Wrap(func() { protocol.TCPServer(s.tcpListener, tcpServer) ... }) if s.ctx.GetTlsConfig() != nil && opts.HTTPSAddress != "" { ... httpsServer := newHTTPServer(s.ctx, true, true) s.waitGroup.Wrap(func() { http_api.Serve(s.httpsListener, httpsServer, "HTTPS", opts.Logger) }) } ... httpServer := newHTTPServer(s.ctx, false, opts.TLSRequired == TLSRequired) s.waitGroup.Wrap(func() { http_api.Serve(s.httpListener, httpServer, "HTTP", opts.Logger) }) ... }
|
2.2.1.TCP监听
TCPServer 函数跟之前分析过的很多服务启动类似,都是在一个循环里不断 Accept 接受连接,并调用 tcpServer 实现的 Handle 接口进行处理。源码位于 internal\protocol\tcp_server.go 文件中,如下:
1 2 3 4 5 6 7
| func TCPServer(listener net.Listener, handler TCPHandler) { for { clientConn, err := listener.Accept() ... go handler.Handle(clientConn) } }
|
2.2.2.HTTP监听
newHTTPServer 的流程也类似,先注册URL和对应的回调函数。源码位于 nsqdserver\http.go,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| func newHTTPServer(ctx *context, tlsEnabled bool, tlsRequired bool) *httpServer { ... router := httprouter.New() ... s := &httpServer{ ctx: ctx, tlsEnabled: tlsEnabled, tlsRequired: tlsRequired, router: router, } router.Handle("GET", "/ping", http_api.Decorate(s.pingHandler, log, http_api.PlainText)) ... return s }
|
然后调用 Serve 函数,创建 Server 对象,并调用其 Serve 方法,完成监听并接受请求。源码位于 internal\http_api\http_server.go,如下:
1 2 3 4 5 6 7 8 9 10 11
| func Serve(listener net.Listener, handler http.Handler, proto string, l levellogger.Logger) { ... server := &http.Server{ Handler: handler, ErrorLog: log.New(logWriter{l}, "", 0), ReadTimeout: 10 * time.Second, WriteTimeout: 60 * time.Second, } err := server.Serve(listener) ... }
|
Server结构体的 Serve 方法是 Golang 标准库的代码,也是在一个循环里不断 Accept 客户端的请求。源码如下:
1 2 3 4 5 6 7 8 9 10
| func (srv *Server) Serve(l net.Listener) error { ... for { rw, err := l.Accept() ... c := srv.newConn(rw) c.setState(c.rwc, StateNew) go c.serve(connCtx) } }
|
2.3.提交消息到Topic
由于 NSQ 支持 HTTP 提交消息,所以选择从 HTTP 的 URL 为起点,寻找提交消息的具体业务逻辑,应该是一个更直观、更有效的方式。这里参考官方给出的 HTTP API 文档,可以看到提交消息到Topic对应的 URL 是 /pub。相应的可以在 nsqdserver\http.go 的 newHTTPServer 函数中找到 URL 对应的回调函数 doPUB。
同时,有赞版本的 NSQ 新增了 /pub_ext 和 /pubtrace,以上三者本质上都是调用了 internalPUB 方法,应该是用以支持有赞团队提到的 消息轨迹查询系统。
2.3.1.消费channel的数据同步处理
官方版本之所以要从topic复制所有消息到每个channel,是因为使用的是golang里面的chan这种机制,只有复制才能保证每个消费组的数据互相独立。
有赞版本则是将数据先进行落盘,所以不再需要做这种数据复制的操作,只需要记录每个channel已经同步的数据位移和每个channel的消费位移即可。这样所有的channel引用的是同一份topic磁盘数据,每个channel维护自己的独立位移信息即可。
优点:
- 节省了数据复制的操作,提高了性能,也保证了各个channel之间的独立性。
- 从流程上看,有赞版本把topic的写入和读取流程分离开了,topic本身只负责写入数据,channel仅负责读取数据。
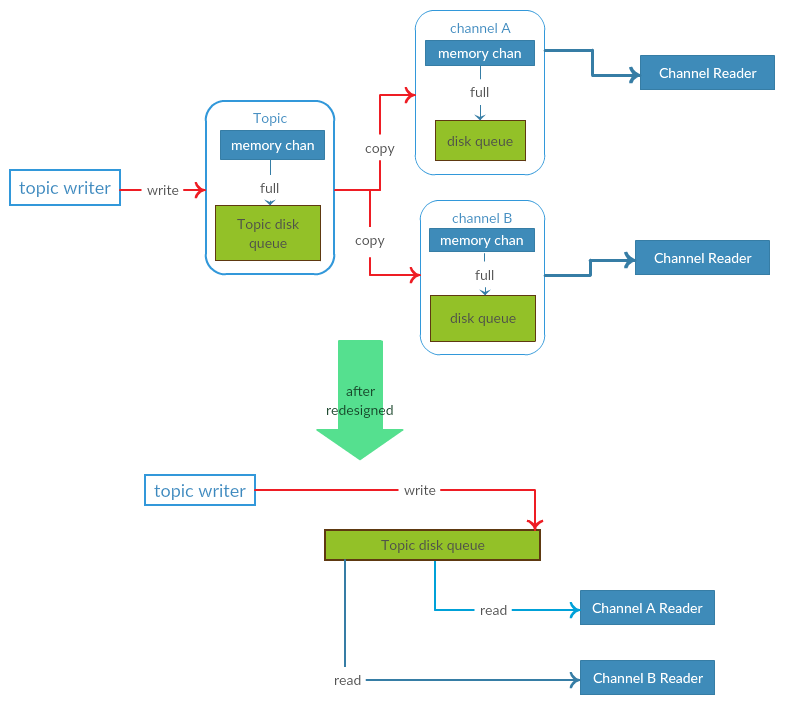
官方版 NSQ 的设计目标之一就是要限定保持在内存中的消息数。它通过 DiskQueue 透明地将溢出的消息写入到磁盘上。所以有上图的 full 之后再落盘数据。接下来,先以单机的提交消息到Topic为例,看看代码层面如何实现落盘的。
2.3.2.internalPUB方法
先来看看 internalPUB 方法具体做了什么。该方法将 req.Body 的内容拷贝到缓存中,主节点按照是否为异步提交的策略,选择不同的提交方式,并根据需要跟踪相关信息;从节点则不执行这部分逻辑。源码依旧位于 nsqdserver\http.go,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44
| func (s *httpServer) internalPUB(w http.ResponseWriter, req *http.Request, ps httprouter.Params, enableTrace bool, pubExt bool) (interface{}, error) { ... params, topic, err := s.getExistingTopicFromQuery(req) ... n, err := io.CopyN(b, io.LimitReader(req.Body, readMax), int64(req.ContentLength)) body := b.Bytes()[:req.ContentLength] ... if s.ctx.checkForMasterWrite(topic.GetTopicName(), topic.GetTopicPart()) { ... ... if asyncAction { err = internalPubAsync(nil, body, topic, extContent) } else { id, offset, rawSize, _, err = s.ctx.PutMessage(topic, body, extContent, traceID) } ... ... if needTraceRsp { return struct { Status string `json:"status"` ID uint64 `json:"id"` TraceID string `json:"trace_id"` QueueOffset uint64 `json:"queue_offset"` DataRawSize uint32 `json:"rawsize"` }{"OK", uint64(id), traceIDStr, uint64(offset), uint32(rawSize)}, nil } else { return "OK", nil } } else { ... return nil, http_api.Err{400, FailedOnNotLeader} } }
|
2.3.3.internalPubAsync函数
这就来到了有赞团队在How we redesigned the NSQ - NSQ重塑之详细设计一文中提到的关键函数——internalPubAsync 函数,该函数位于 nsqdserver\protocol_v2.go。
在服务端引入常见的Group commit组提交方式,将多个消息一次性提交,减少IO操作。这样不管是因为刷盘还是因为数据副本同步的延迟,都会把这段时间的积累的多个消息作为一组一次性写入,这样就大大减少了需要操作的写入次数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
| func internalPubAsync(clientTimer *time.Timer, msgBody []byte, topic *nsqd.Topic, extContent ext.IExtContent) error { if topic.Exiting() { return nsqd.ErrExiting } info := &nsqd.PubInfo{ Done: make(chan struct{}), MsgBody: msgBody, ExtContent: extContent, StartPub: time.Now(), } select { case topic.GetWaitChan() <- info: default: if clientTimer == nil { clientTimer = time.NewTimer(pubWaitTimeout) } else { clientTimer.Reset(pubWaitTimeout) } select { case topic.GetWaitChan() <- info: case <-topic.QuitChan(): nsqd.NsqLogger().Infof("topic %v put messages failed at exiting", topic.GetFullName()) return nsqd.ErrExiting case <-clientTimer.C: nsqd.NsqLogger().Infof("topic %v put messages timeout ", topic.GetFullName()) topic.IncrPubFailed() incrServerPubFailed() return ErrPubToWaitTimeout } } <-info.Done return info.Err }
|
2.3.4.internalPubLoop方法
通过 topic.GetWaitChan(),可以找到 PubInfo 结构体被发送到了哪里。可以看到,数据被发送到了 internalPubLoop 方法。
组提交循环,在chan上面等待异步提交写入请求,并尝试一次提交所有等待中的请求。请求完成后,通过关闭对应请求的chan来通知客户端结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64
| func (c *context) internalPubLoop(topic *nsqd.Topic) { messages := make([]*nsqd.Message, 0, 100) pubInfoList := make([]*nsqd.PubInfo, 0, 100) ... defer func() { done := false for !done { select { case info := <-topic.GetWaitChan(): pubInfoList = append(pubInfoList, info) default: done = true } } nsqd.NsqLogger().Logf("quit pub loop for topic: %v, left: %v ", topic.GetFullName(), len(pubInfoList)) for _, info := range pubInfoList { info.Err = nsqd.ErrExiting close(info.Done) } }() quitChan := topic.QuitChan() infoChan := topic.GetWaitChan() for { select { case <-quitChan: return case info := <-infoChan: ... if !topic.IsExt() { messages = append(messages, nsqd.NewMessage(0, info.MsgBody)) } else { messages = append(messages, nsqd.NewMessageWithExt(0, info.MsgBody, info.ExtContent.ExtVersion(), info.ExtContent.GetBytes())) } pubInfoList = append(pubInfoList, info) default: if len(pubInfoList) == 0 { ... continue } var retErr error if c.checkForMasterWrite(topicName, partition) { s := time.Now() _, _, _, err := c.PutMessages(topic, messages) ... } else { ... } ... for _, info := range pubInfoList { info.Err = retErr close(info.Done) } pubInfoList = pubInfoList[:0] messages = messages[:0] } } }
|
上述方法是如何运行起来的,可以参考 nsqd\topic.go 文件,是在New出一个新的Topic时,将该方法作为 Topic 结构体的成员变量,并起一个协程调用该方法。
可以看到,上述方法只是接受数据,再存到数组中,并统一进行落盘处理,而具体的落盘方法是 PutMessages 方法。通过 Goland 的代码转跳,可以很容易地找到最终的刷盘代码,是位于 nsqd\diskqueue_writer.go 的 func (d *diskQueueWriter) writeOne(...) (...)。可以看到文件名,基本上跟图片上的 Topic Disk Queue 对应上了。
2.4.支持数据副本和高可用
这部分做了类似Kafka的设计,将每个topic的数据节点副本元信息写入etcd,然后通过etcd选举出每个topic的leader节点。选举的topic的leader节点负责自己topic的数据副本同步,其他follower节点从leader节点同步topic数据。
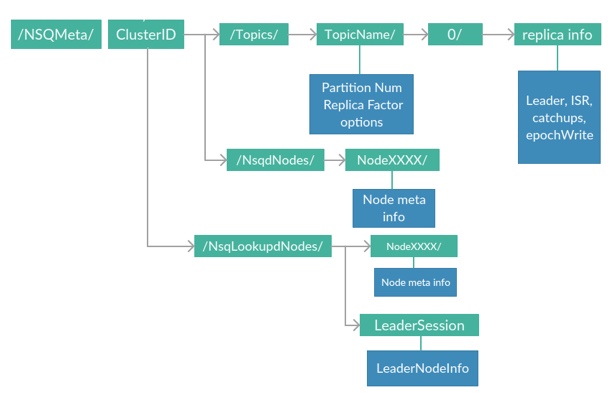
2.4.1.元数据存储
一些少量的元数据存储在etcd,保证整个集群的元数据的一致性。
具体包括每个topic的配置信息,副本节点的分布,选举出来的leader节点信息,nsqd数据节点的配置信息以及nsqlookupd数据查询节点的配置信息。元数据树结构图如下:
2.4.2.Leader选举
改造后的nsq架构,每个topic需要一个leader节点负责处理读写请求和数据同步。为了保证每个节点的负载趋于均衡,我们通过nsqlookupd来选择合适的topic的leader节点,并通知给所有副本进行leader确认。leader节点会尝试从etcd获取topic对应的leader锁确认leader有效。
当某个节点失效时,会触发etcd的watch事件,从而触发nsqlookupd重新选择其他存活的节点作为topic的新leader,完成leader的快速切换。客户端如果此时正在写入老的leader也会触发失败重试,并获取最新的leader节点,完成自动HA。选举具体流程如下:
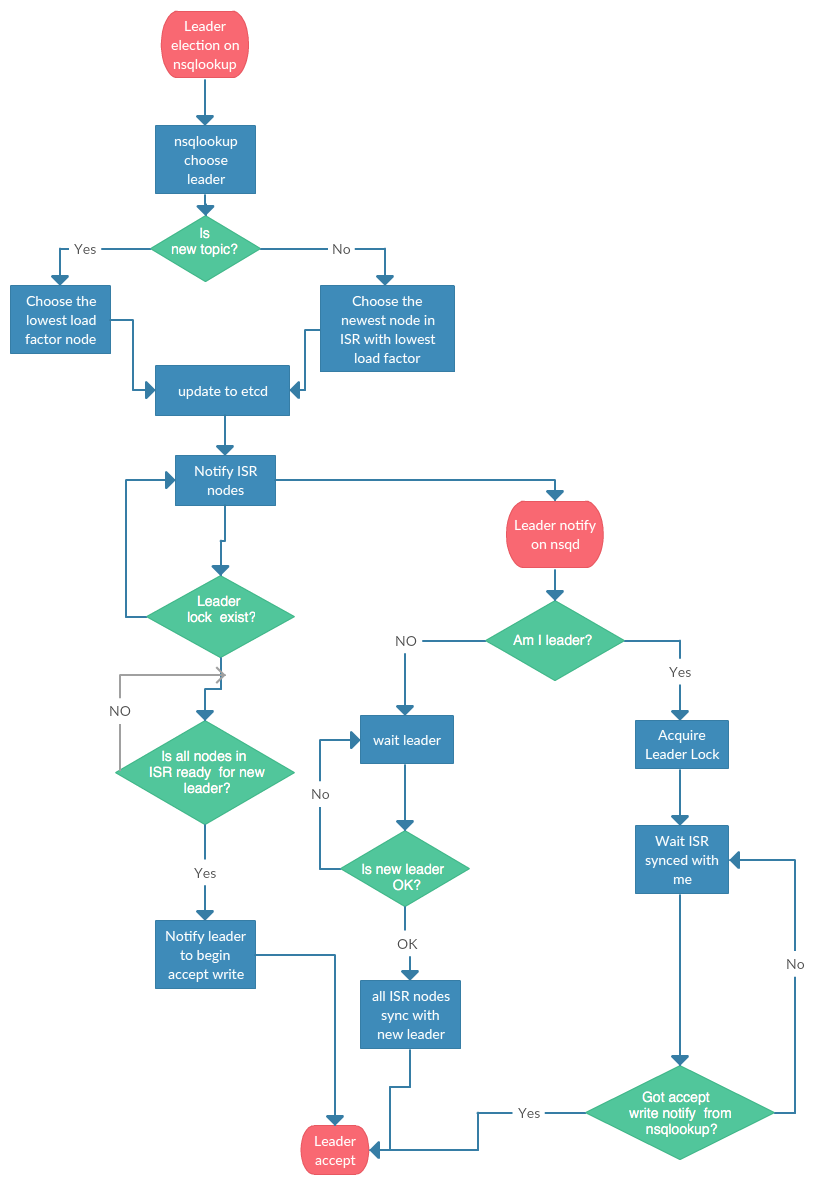
2.4.3.从代码角度进行大致梳理
在 nsqlookupd 启动的时候,会启动一个名为 NsqLookupCoordinator 的实例,由它进行 Leader 节点的选举工作。可以看到它的 Start 方法在 NSQLookupd 的 Main 方法中被调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
| func (l *NSQLookupd) Main() { ... if l.opts.RPCPort != "" { ... err = l.coordinator.Start() ... } else { ... } ... httpListener, err := net.Listen("tcp", l.opts.HTTPAddress) ... httpServer := newHTTPServer(ctx) ... }
|
下述方法的源码均在 consistence\nsqlookup_coordinator.go 中,在 NsqLookupCoordinator 的 Start 方法中,启动一个协程去处理 Leader 选举的工作。代码如下:
1 2 3 4 5 6
| func (nlcoord *NsqLookupCoordinator) Start() error { ... go nlcoord.handleLeadership() ... return nil }
|
在 NsqLookupCoordinator 的 handleLeadership 方法中,主要就是循环监听 Leader 节点的变化,特别是在 Leader 发生改变时,发出 Leader 改变的通知。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
| func (nlcoord *NsqLookupCoordinator) handleLeadership() { ... for { select { case l, ok := <-lookupdLeaderChan: if !ok { coordLog.Warningf("leader chan closed.") return } if l == nil { coordLog.Warningln("leader is lost.") continue } if l.GetID() != nlcoord.leaderNode.GetID() || l.Epoch != nlcoord.leaderNode.Epoch { nlcoord.leaderNode = *l ... nlcoord.notifyLeaderChanged(nlcoord.nsqdMonitorChan) } if nlcoord.leaderNode.GetID() == "" { coordLog.Warningln("leader is missing.") } case <-ticker.C: _, err := nlcoord.leadership.ScanTopics() ... } } }
|
可以看到上述代码中,调用了 notifyLeaderChanged 方法,其中又调用了 checkTopics,实际上它也是调用 doCheckTopics 进行处理。而 doCheckTopics 方法中,有一些重要的东西。通过源码本身的注释,可以看到其中有一句,如果 Leader 宕机了,就需要先选举一个新的 Leader ,这里应该就是选举的算法了。而根据之前的选举具体流程图来看,该方法应该是主干部分。其源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
| func (nlcoord *NsqLookupCoordinator) doCheckTopics(monitorChan chan struct{}, failedInfo *TopicNameInfo, waitingMigrateTopic map[string]map[int]time.Time, lostLeaderSessions map[string]bool, fullCheck bool) { ... for _, t := range topics { ... coordErr := nlcoord.handleRemoveFailedISRNodes(failedNodes, &topicInfo) ... if _, ok := currentNodes[t.Leader]; !ok { ... coordErr := nlcoord.handleTopicLeaderElection(&topicInfo, aliveNodes, aliveEpoch, false) ... continue } else { ... for retry < 3 { retry++ leaderSession, err = nlcoord.leadership.GetTopicLeaderSession(t.Name, t.Partition) if err != nil { ... nlcoord.notifyISRTopicMetaInfo(&topicInfo) nlcoord.notifyAcquireTopicLeader(&topicInfo) ... continue } else { break } } ... if leaderSession.LeaderNode == nil || leaderSession.Session == "" { ... nlcoord.notifyISRTopicMetaInfo(&topicInfo) nlcoord.notifyAcquireTopicLeader(&topicInfo) continue } if leaderSession.LeaderNode.ID != t.Leader { ... nlcoord.notifyISRTopicMetaInfo(&topicInfo) nlcoord.notifyAcquireTopicLeader(&topicInfo) continue } } ... } ... }
|
handleTopicLeaderElection 方法的源码就不在这里列出,继续按照流程图进行梳理。可以看到上面的代码里调用了 notifyAcquireTopicLeader 方法,其中以回调的方式,调用 sendAcquireTopicLeaderToNsqd,最终调用到 NsqdRpcClient 的 NotifyAcquireTopicLeader 方法完成通知 Leader 节点获取 Leader 锁。NsqdRpcClient 以 RPC 的方式,调用 Leader 节点的 NotifyAcquireTopicLeader方法。NotifyAcquireTopicLeader 源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| func (self *NsqdCoordRpcServer) NotifyAcquireTopicLeader(rpcTopicReq *RpcAcquireTopicLeaderReq) *CoordErr { ... if err := self.checkLookupForWrite(rpcTopicReq.LookupdEpoch); err != nil { ... } ... topicCoord, err := self.nsqdCoord.getTopicCoord(rpcTopicReq.TopicName, rpcTopicReq.TopicPartition) ... tcData := topicCoord.GetData() ... err = self.nsqdCoord.notifyAcquireTopicLeader(tcData) ... return &ret }
|
可以看到上述代码是根据 TopicName 和 TopicPartition 查询到 NsqdCoordinator,实际上是调用它的 acquireTopicLeader 方法去获取 Leader 锁。源码位于 consistence\nsqd_coordinator.go,如下:
1 2 3 4 5 6 7 8 9 10 11 12
| func (ncoord *NsqdCoordinator) acquireTopicLeader(topicInfo *TopicPartitionMetaInfo) *CoordErr { ... err := ncoord.leadership.AcquireTopicLeader(topicInfo.Name, topicInfo.Partition, &ncoord.myNode, topicInfo.Epoch) if err != nil { coordLog.Infof("failed to acquire leader for topic(%v): %v", topicInfo.Name, err) return &CoordErr{err.Error(), RpcNoErr, CoordElectionErr} } coordLog.Infof("acquiring leader for topic(%v) success", topicInfo.Name) return nil }
|
AcquireTopicLeader 的源码位于 consistence\nsqd_node_etcd.go,尝试从 ETCD 中读取 Leader 锁,如果不存在,则尝试创建。如果创建失败,就表示获锁失败;如果创建成功,则表示成为 Leader 节点。源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
| func (nem *NsqdEtcdMgr) AcquireTopicLeader(topic string, partition int, nodeData *NsqdNodeInfo, epoch EpochType) error { topicLeaderSession := &TopicLeaderSession{ ... } valueB, err := json.Marshal(topicLeaderSession) ... topicKey := nem.createTopicLeaderPath(topic, partition) rsp, err := nem.client.Get(topicKey, false, false) if err != nil { if client.IsKeyNotFound(err) { coordLog.Infof("try to acquire topic leader session [%s]", topicKey) rsp, err = nem.client.Create(topicKey, string(valueB), 0) if err != nil { coordLog.Infof("acquire topic leader session [%s] failed: %v", topicKey, err) return err } coordLog.Infof("acquire topic leader [%s] success: %v", topicKey, string(valueB)) return nil } else { ... return err } } if rsp.Node.Value == string(valueB) { coordLog.Infof("get topic leader with the same [%s] ", topicKey) return nil } coordLog.Infof("get topic leader [%s] failed, lock exist value[%s]", topicKey, rsp.Node.Value) return ErrKeyAlreadyExist }
|
2.5.数据副本同步和动态ISR
每个topic选举出来的leader节点负责同步数据到所有副本。为了支持副本节点的动态变化,参考了Kafka的ISR(In synced replica)的设计。和Kafka不同的是,有赞版本用push模式,不是pull的模式,来保证数据的同步复制,避免数据同步不一致。
因此,数据写入首先由leader节点发起,并且同步到所有ISR副本节点成功后,才返回给客户端。如果同步ISR节点失败,则尝试动态调整ISR并重试直到成功为止。重试的过程中会检查leader的有效性,以及是否重复提交等条件。写入流程和ISR的动态调整流程如图所示:
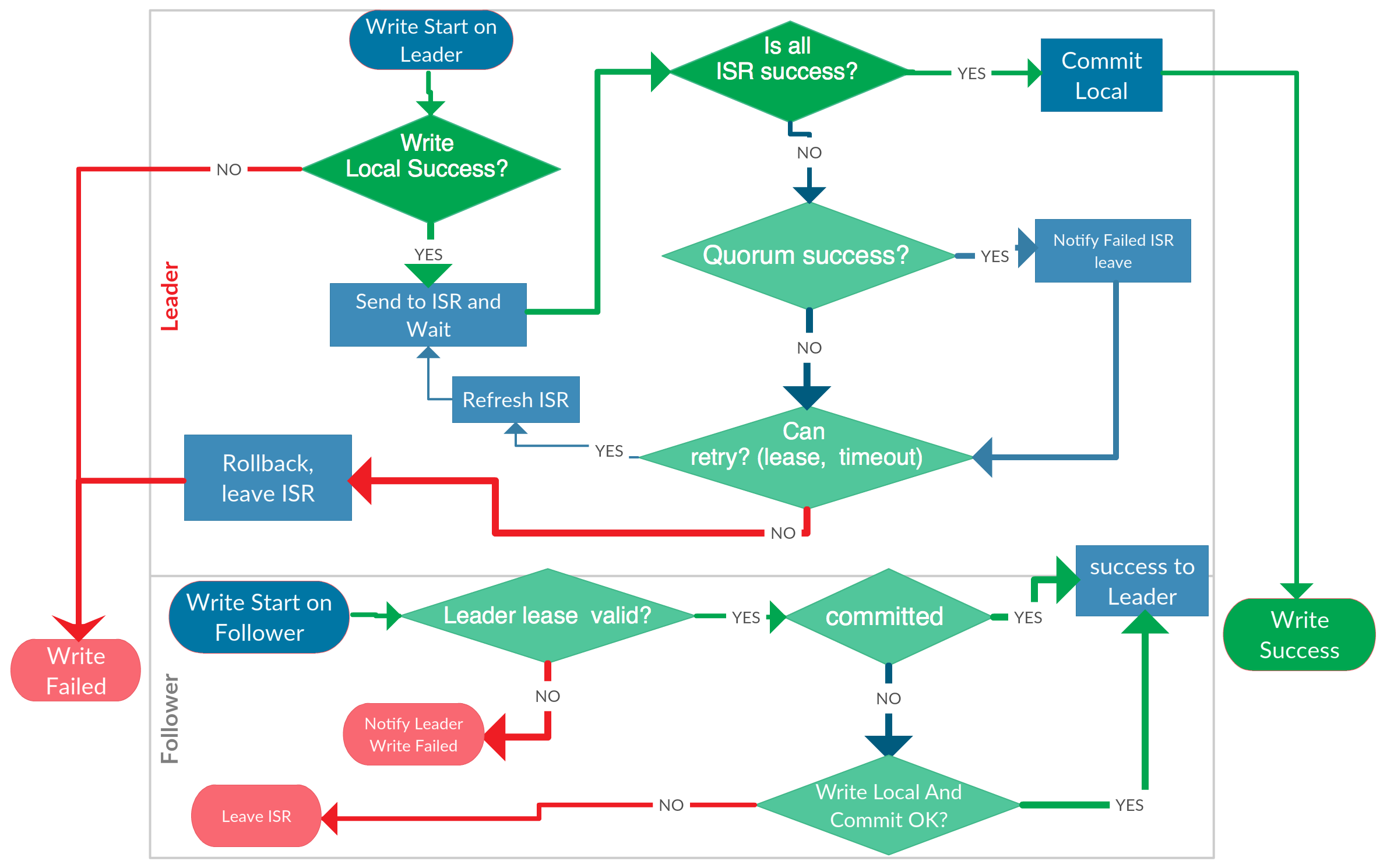
2.5.1.从代码角度进行大致梳理
从之前对 internalPUB 的分析可以看到,同步消息是使用 PutMessage 提交的;而从对 internalPubLoop 的分析可以看到,异步消息是使用 PutMessages 提交的。
两段代码都位于 nsqdserver\context.go 中,以后者为例,可以看到单机使用 Topic 的 PutMessages;而集群模式时,则使用 NsqdCoordinator 的 PutMessagesToCluster 方法。源码如下:
1 2 3 4 5 6 7
| func (c *context) PutMessages(topic *nsqd.Topic, msgs []*nsqd.Message) (nsqd.MessageID, nsqd.BackendOffset, int32, error) { if c.nsqdCoord == nil { id, offset, rawSize, _, _, err := topic.PutMessages(msgs) return id, offset, rawSize, err } return c.nsqdCoord.PutMessagesToCluster(topic, msgs) }
|
NsqdCoordinator 的 PutMessagesToCluster 方法位于 consistence\nsqd_coordinator_cluster_write.go 文件中,可以看到其中定义了多个回调方法,例如 doLocalWrite、doLocalExit、doLocalCommit、doLocalRollback、doRefresh、doSlaveSync、handleSyncResult,基本都可以在上图中找到一个对应的步骤。源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
| func (ncoord *NsqdCoordinator) PutMessagesToCluster(topic *nsqd.Topic, msgs []*nsqd.Message) (nsqd.MessageID, nsqd.BackendOffset, int32, error) { ... doLocalWrite := func(d *coordData) *CoordErr { ... } doLocalExit := func(err *CoordErr) { ... } doLocalCommit := func() error { ... } doLocalRollback := func() { ... } doRefresh := func(d *coordData) *CoordErr { ... } doSlaveSync := func(c *NsqdRpcClient, nodeID string, tcData *coordData) *CoordErr { if isTestSlaveTimeout() { return NewCoordErr("timeout test for slave sync", CoordNetErr) } putErr := c.PutMessages(&tcData.topicLeaderSession, &tcData.topicInfo, commitLog, msgs) ... return putErr } handleSyncResult := func(successNum int, tcData *coordData) bool { ... } clusterErr := ncoord.doSyncOpToCluster(true, coord, doLocalWrite, doLocalExit, doLocalCommit, doLocalRollback, doRefresh, doSlaveSync, handleSyncResult) ... return nsqd.MessageID(commitLog.LogID), nsqd.BackendOffset(commitLog.MsgOffset), commitLog.MsgSize, err }
|
doSyncOpToCluster 方法同样位于 consistence\nsqd_coordinator_cluster_write.go 文件中,由于代码比较长,这里就不列出了,其中的业务逻辑跟上图基本是一致的。
接下来具体看看主从节点是如何进行数据同步的。在上述方法的 doSlaveSync 变量中,可以看到回调函数是调用了根据 nodeId 找到的 NsqdRpcClient 的 PutMessages 方法,这其实是一个 gRPC 的客户端方法,进而可以找到对应的 Server 名为 nsqdCoordGRpcServer,对应的方法是位于 consistence\coord_grpc_server.go 文件中的 PutMessages 方法。
PutMessages 方法会解析 RPC 请求里的数据,并调用 putMessagesOnSlave 方法,去构建回调函数。源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| func (s *nsqdCoordGRpcServer) PutMessages(ctx context.Context, req *pb.RpcPutMessages) (*pb.CoordErr, error) { ... tc, err := s.nsqdCoord.checkWriteForGRpcCall(req.TopicData) ... commitData := fromPbCommitLogData(req.LogData) var msgs []*nsqd.Message for _, pbm := range req.TopicMessage { var msg nsqd.Message ... msgs = append(msgs, &msg) } err = s.nsqdCoord.putMessagesOnSlave(tc, commitData, msgs) ... return &coordErr, nil }
|
重新回到 consistence\nsqd_coordinator_cluster_write.go 文件中,putMessagesOnSlave 方法主要是定义了回调函数,例如 checkDupOnSlave、doLocalWriteOnSlave、doLocalCommit、doLocalExit。源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| func (ncoord *NsqdCoordinator) putMessagesOnSlave(coord *TopicCoordinator, logData CommitLogData, msgs []*nsqd.Message) *CoordErr { ... checkDupOnSlave := func(tc *coordData) bool { ... } doLocalWriteOnSlave := func(tc *coordData) *CoordErr { ... topic, localErr = ncoord.localNsqd.GetExistingTopic(topicName, partition) ... topic.Lock() ... queueEnd, localErr = topic.PutMessagesOnReplica(msgs, nsqd.BackendOffset(logData.MsgOffset), int64(logData.MsgSize)) ... topic.Unlock() ... } doLocalCommit := func() error { ... } doLocalExit := func(err *CoordErr) { ... } return ncoord.doWriteOpOnSlave(coord, checkDupOnSlave, doLocalWriteOnSlave, doLocalCommit, doLocalExit) }
|
同样,doWriteOpOnSlave 方法,由于代码比较长,这里就不列出了,其中的业务逻辑跟上图基本是一致的。
更多细节,可以参考How we redesigned the NSQ - NSQ重塑之详细设计的 数据副本同步和动态ISR 部分。
到这里为止,基本上算是解决了官方版本 NSQ 的最大问题——节点异常情况下的数据丢失的问题,可以将不同分区复制到不同节点,且每个分区单独选举 Leader 节点,
2.6.严格顺序消费
2.6.1.存在的问题
默认的消费模式,是允许多个客户端链接同时消费topic下的同一个分区的不同消息的,这样可以使用最小的分区数来达到较高的并发消费能力。
优点:
- 避免了像Kafka那样为了提高消费能力,创建过多的分区,从而避免了过多分区数带来的磁盘随机IO问题。
缺点:
2.6.2.解决方式
对于需要保证消息严格按照生产写入的顺序进行投递的场景,有赞引入了顺序投递的特性。
- 在生产方也支持按照业务定制id进行分区hash的生产能力,从而保证从生产到消费整条链路是按照分区内有序的方式进行消息流转的。
- 消息生产方会根据业务的分区id将同样的id投递到同一个topic分区,保证相同id的数据的顺序一致性。
- 而在投递时,会调整并发消费策略,保证同一时刻只会投递一条消息进行消费,等待上一次ack成功后才继续投递下一条消息。
- 同时,为了避免leader切换时影响消息的顺序性,ack的消息还会同步到所有副本才算成功。
然而也会存在跟Kafka相似的缺点,单个分区的消费并发能力不如乱序消费,主要取决于消费业务本身的处理能力,为了提高更高的顺序消费并发能力,需要更多的分区数。
2.7.消息轨迹查询系统
之前的NSQ系统由于消息在chan里面流转一遍就没了,很难事后进行数据追查,也没有一个很好的方式去跟踪一条消息在从生产到被消费的各种中间状态。
为了满足业务方时不时的来排查业务消息状态的需求,有赞改造后的NSQ也支持动态的开启这种消息轨迹排查功能。为了支持消息轨迹查询,有赞团队做了如下几个工作:
- 能通过消息id定位到磁盘上的消息内容;
- 支持传入业务traceId, 并将业务traceId和nsq的消息id关联起来;
- 记录一条消息的所有中间态变化信息;
- 将消息的状态变迁信息同步到ES搜索系统;
- nsqadmin提供方便的统一查询入口;
- 支持针对topic和channel级别的动态跟踪开关以减少资源消耗。
通过这一套轨迹查询系统,在业务方需要排查问题的时候,就能非常快速的找到异常消息的轨迹从而快速的定位业务问题了。特别是在排查顺序消费的业务场景时,经常能发现业务潜在的并发误用问题。
2.8.其他特性
参考How we redesigned the NSQ - NSQ重塑之详细设计,可以看到有赞版本的NSQ还有 自动数据平衡、分区支持、改造消费channel、处理重试和延时消费、消费数据预读优化、重放历史数据 等特点。
另外,参考How we redesigned the NSQ - 其他特性及未来计划,还可以看到 NSQ拓展消息格式的设计、nsq迁移工具 等。
3.参考资料
为何要抛弃Kafka,选择NSQ!
走进 NSQ 源码细节
官方文档 - 组件 - NSQD
How we redesigned the NSQ - Overview
How we redesigned the NSQ - NSQ重塑之详细设计
How we redesigned the NSQ - 其他特性及未来计划
4.结语
这是在实习过程中学习到的新知识,且全部是开源数据或者资料,因此分享出来,希望我和大家都有所收获。最终,这部分的学习也成为了我实习答辩的重要材料,对我帮助非常大。并帮助我完成了事件中心的 Agent 落盘部分的代码,用自己的学习帮助到了团队。
参考资料已经在文中列出,这里不再一一列举。
转载请注明出处,无偿提供。
